mknals programming (under construction) |
 |
mknals programming (under construction) |
|
Our team presented our solution T4T for the Shared Task: Similar Language Translation for the WMT21 (EMNLP 2021 6th Conference on MT that was hold Nov 2021) (HTTP://www.statmt.org/wmt21/similar.html)
This task is related to the translation between similar language pairs (in our case for ES<>CA and ES<>PT).
We focused on the corpus cleaning (both from "physical" and "statistical" point of view). Also we tried a word segmentation alternative (syllabic) to byte-pair-encoding (BPE). Finally we used OpenNMT to create our MT model.
We have found that after a good "physical" cleaning, other recipes as "statistical" cleaning (trying to remove translations with low probability related to a corpus dictionary) or alternatives to BPE (as the syllabic segmentation) provided little or unclear improvements.
We have used less demanding OpenNMT RNN models for tinning and evaluation, and only for the final election, used the Transformer model. This means we have used a reasonable local environment (2 x 8 GB GPUs in a 48Gb i7) thru all this process.
Final result has been based in common sense, that is: clean the corpus as much as we can, use standard techniques as BPE in order to reduce vocabulary and a proven toolkit as OpenNMT with the Transformer model.
The result of the competition has been that our system has been always close to the top if not the best one. These are good news in the sense that you still can get state of the art results with tools using reasonable power. In the following table you can compare our results (column T4T) against the other participants (Best score). Notice how close are the results (if not the best).
| BLEU | RIBES | TER | ||||
| Best score | T4T | Best score | T4T | Best score | T4T | |
| PT-ES | 47.71 | 46.29 | 87.11 | 87.04 | 39.21 | 40.18 |
| ES-PT | 40.74 | 40.74 | 85.69 | 85.69 | 43.34 | 43.34 |
| CA-ES | 82.79 | 77.93 | 96.98 | 96.04 | 10.92 | 16.50 |
| ES-CA | 79.69 | 78.60 | 96.24 | 96.24 | 14.63 | 16.13 |
The results reinforce the idea that if you have a clean and coherent corpus your results will be pretty good with OpenNMT.
Even is not written anywhere, in our opinion ES-CA and ES-PT should have similar scores as they are very close languages (notice the 30-40 points differences), We highly suspect the difference is due the corpus, showing again its importance.
The tech paper we submitted for the WMT21 schedule (https://www.statmt.org/wmt21/program.html ) -> ( T4T Solution: WMT21 Similar Language Task for the Spanish-Catalan and Spanish-Portuguese Language Pair (Link-> https://www.statmt.org/wmt21/pdf/2021.wmt-1.28.pdf))
If you wish to get a general idea ot the solution, I strongly suggest you to check the tech paper.
If you what to get a sense of what we have donde, probably you can follow on.
Again, unless you are interested about details of the solution you can skip the rest of the document.
This doc provides a general ideal. Does not intent to be complete nor provide any code right now.
Also be aware that the evaluation data (the one we should use to find the actual scores) has not been released yet (as per march 22), so the results of this doc are based in the evaluation data of last year (but results are should be similar as the ones achieved in the conference results).
You will also notice some references to several python programs. Most of them are conceptually easy programs to understand, so only a general idea will be given.
Source data was provided by the organization in https://wmt21similar.cs.upc.edu/. If anyone is interested I can share this data.
| Europarl v10 | europarl-v10.es-pt.tsv |
| News Commentary v16 | news-commentary-v16.es-pt.tsv |
| Wiki Titles v3 | wikititles-v3.es-pt.tsv |
| Tilde MODEL | TildeMODEL.es-pt.es / TildeMODEL.es-pt.pt |
| JRC-Acquis | JRC-Acquis.es-pt.es / JRC-Acquis.es-pt.pt |
Notice how we need to split the tsv in es/pt files (tsv are tab files). We used a script to split the tab value file (ad_SplitsTab.py) to create the parallel files
>europarl-v10.es
copy *.pt pt /B copy *.es es /B
or
cat .es es /B cat .pt pt /B
Unfortunately the corpus has many strings that look are tokenized, so we need to detokenize the files. The ways to detokenize the file is using the Moses detokenizer. This script will change some punctuation chars, so is a side effect that be take in account as not desirable.
Detokenize:
perl /home/laika/OpenNMT-py/tools/detokenize.perl -l es
< /home/laika/unetbios/u_Mlai32/21_T4T/02_py/02_bitext/data4/es
> /home/laika/unetbios/u_Mlai32/21_T4T/02_py/02_bitext/data4/dkt.es
perl /home/laika/OpenNMT-py/tools/detokenize.perl -l es
< /home/laika/unetbios/u_Mlai32/21_T4T/02_py/02_bitext/data4/pt
> /home/laika/unetbios/u_Mlai32/21_T4T/02_py/02_bitext/data4/dkt.pt
Remove duplicates lines (we use a script gg_RemoveDup.py)
dtk.es->
dtk.es.ddup
dtk.pt->
dtk.pt.ddup
Shuffle the lines (we use a script hm_shuffle_bitex.py)
dtk.es.ddup ->
dtk.es.ddup.shf
dtk.pt.ddup ->
dtk.pt.ddup.shf
The corpus has 3.8 M lines
Beside the corpus, organization provides dev data that we have decided to use to train the model. This file is really small, so idea has been to add this dev data at the beginning of the corpus (our actual dev data will be sourced from the first lines of the corpus).
We detokenize the file as precaution.
perl /home/laika/OpenNMT-py/tools/detokenize.perl -l es
< /home/laika/unetbios/u_Mlai32/21_T4T/02_py/02_bitext/data4/dev.es-pt.es
> /home/laika/unetbios/u_Mlai32/21_T4T/02_py/02_bitext/data4/dkt.dev.es-pt.es
perl /home/laika/OpenNMT-py/tools/detokenize.perl -l es
< /home/laika/unetbios/u_Mlai32/21_T4T/02_py/02_bitext/data4/dev.es-pt.pt
> /home/laika/unetbios/u_Mlai32/21_T4T/02_py/02_bitext/data4/dkt.dev.es-pt.pt
We deduplicate the file as precaution (we use a script gg_RemoveDup.py)
dkt.dev.es-pt.es ->
dkt.dev.es-pt.es.ddup
dkt.dev.es-pt.pt ->
dkt.dev.es-pt.pt.ddup
We shuffle (we use a script hm_shuffle_bitex.py)
dkt.dev.es-pt.es.ddup
-> dkt.dev.es-pt.es.ddup.shf
dkt.dev.es-pt.pt.ddup
-> dkt.dev.es-pt.pt.ddup.shf
Finally we join dev data with corpus:
cat dkt.dev.es-pt.es.ddup.shf dkt.es.ddup.shf > es.dtk cat dkt.dev.es-pt.pt.ddup.shf dkt.pt.ddup.shf > pt.dtk
Our starting point is es.dtk and pt.dtk
We will perform a physical cleaning. These are ad-hoc tasks based on a manual inspection of the corpus:
- Sentences must to start with a char. (strings removed until char)
- Remove some (BAR) in bitext
- Sentence has to
have a hunspell valid word en each line.
- Remove starting
strings from sentences 123 .
- Remove starting strings from
sentences starting xxx)
- Remove any instances of (text
text.... )
- Remove any blank string
- Remove duplicates
The result is:
es.dtk ->
es.dtk.0
pt.dtk ->
pt.dtk.0
We verify in es.dtk.0 and pt.dtk.0 all sentences in order to be splitted as sentences with nltk. If we do so, we ignore these sentences (probably 2 sentences or a translation as 2 sentences).
es.dtk.0 ->
es.dtk.clean
pt.dtk.0 ->
pt.dtk.clean
We will use a special tokenizer, that will tokenize all special chars from a token list file we will create first.
We create a working temporary file with the corpus (es.dtk.clean and pt.dtk.clean). The program we use is bc_normalizer_V02.py. The tokenizer uses an optional first phase in order to find the tokens it can use (with the special option "CREATELIST") that will generate a list of the split tokens (file *.tkl and *.tkl.error). As an example, this are the result of the first lines of *.tkl.freq for the full corpus (the token and the frequency)
list.tkl
The clean.tok.err
, 7243770 . 4484344 / 484058 ; 313478 - 300624 : 297728 " 238922 % 114370 ? 103638 ¿ 102222 [ 96742 ] 96470 ) 82760 » 81770
The result file just with the tags we will use for the our tokenizer will be clean.tkl
, . / ; - : " % ? ¿ [ ] ) . . .
Files pt/es.dtk.clean are ready for split in order to run OpenNMT.
But also, there is an optional "statistical" cleaning that will intended to use word probabilities in order to discard sentences with low probabilities. This is covered in 3 Statistical cleaning for PT<>ES
We use a script that will split the file (hm_nlin_splitter.py) that will create 3 x 2 files:
pt/es.dtk.clean.1
(2000 lines, training data)
pt/es.dtk.clean.2
(2000 lines, test data)
pt/es.dtk.clean.3
(2761K lines, corpus)
Note: the start of the corpus contains the dev data from he organization.
We have created a special tokenizer that extracts numbers and assigns variables (ee_normaliza.py using function f_main_tokeniza). This tokenizer extracts numbers and handles correct spacing between special chars.
pt/es.dtk.clean.X
(X=1,2,3) ->
pt/es.dtk.clean.X.tok.tc
( tokenizer and casing)
pt/es.dtk.clean.X.tok.tc.var
(numerical values)
Example:
A Estratégia do Oceano Azul
O anexo I do Regulamento no 588/86 da Comissão, de 28 de Fevereiro de 1986,
relativo à determinação dos direitos niveladores específicos
aplicáveis nas trocas comerciais de carne de bovino no que respeita a Portugal ,
é substituído pelo anexo VII do presente regulamento.
Will be transformed as:
⦅up⦆ a ⦅up⦆ estratégia do ⦅up⦆ oceano ⦅up⦆ azul
⦅up⦆ o anexo ⦅up⦆ i do ⦅up⦆ regulamento no ⦅n0⦆ @@/@@ ⦅n1⦆ da ⦅up⦆ comissão @@, de ⦅n2⦆ de ⦅up⦆ fevereiro de ⦅n3⦆ @@,
relativo à determinação dos direitos niveladores específicos
aplicáveis nas trocas comerciais de carne de bovino no que respeita a ⦅up⦆ portugal ,
é substituído pelo anexo ⦅aup⦆ vii do presente regulamento @@.
In order to feed OpenNMT we need to BPE the files using the google sentencepiece.
Train and encoding (we use es+pt to create our vocabulary)
spm_train --input=pt.dtk.clean.1.tok.tc,es.dtk.clean.1.tok.tc,pt.dtk.clean.2.tok.tc,es.dtk.clean.2.tok.tc
--model_prefix=bpe --vocab_size=16000 --character_coverage=1 --model_type=bpe
-user_defined_symbols=⦅up⦆,⦅aup⦆,⦅n0⦆,⦅n1⦆,⦅n2⦆,⦅n3⦆,⦅n4⦆,⦅n5⦆,⦅n6⦆,⦅n7⦆,⦅n8⦆,⦅n9⦆
spm_encode --model=bpe.model --output_format=piece --extra_options=bos:eos
< pt.dtk.clean.1.tok.tc > pt.dtk.clean.1.tok.tc.sp
spm_encode --model=bpe.model --output_format=piece --extra_options=bos:eos
< es.dtk.clean.1.tok.tc > es.dtk.clean.1.tok.tc.sp
spm_encode --model=bpe.model --output_format=piece --extra_options=bos:eos
< pt.dtk.clean.2.tok.tc > pt.dtk.clean.2.tok.tc.sp
spm_encode --model=bpe.model --output_format=piece --extra_options=bos:eos
< es.dtk.clean.2.tok.tc > es.dtk.clean.2.tok.tc.sp
spm_encode --model=bpe.model --output_format=piece --extra_options=bos:eos
< pt.dtk.clean.3.tok.tc > pt.dtk.clean.3.tok.tc.sp
spm_encode --model=bpe.model --output_format=piece --extra_options=bos:eos
< es.dtk.clean.3.tok.tc > es.dtk.clean.3.tok.tc.sp
As long length for strings is an issue for the neuronal network. We will use another script (hn_maxlinlincropy.py) to delete lines with length greater than 170 tokens (notice lines are tokenized + BPE). This will mean removing less than 5% of the vocabulary but greatly reduces memory consumption on the GPUs.
Final result files are:
pt.dtk.clean.1.tok.tc.sp.170
(training)
es.dtk.clean.1.tok.tc.sp.170
(training)
es.dtk.clean.3.tok.tc.sp.170
(corpus)
pt.dtk.clean.3.tok.tc.sp.170
(corpus)
docker run --rm -it \
--mount type=bind,source="$HOME"/u,target=/u \
--mount type=bind,source="$HOME"/unvme,target=/unmve \
--mount type=bind,source="$HOME"/unetbios/u_Mlai32,target=/u_Mlai32 \
--gpus '"device=0"' \
laika/openmnt:T4T
This is the yaml file for the PT->ES and the Transformer model
## Where the samples will be written
save_data: ptes/run/ptes_bl
## Where the vocab(s) will be written
src_vocab: ptes/run/ptes_bl.vocab.src
tgt_vocab: ptes/run/ptes_bl.vocab.tgt
# Prevent overwriting existing files in the folder
overwrite: False
# Corpus opts:
data:
corpus_1:
path_src: ptes/pt.dtk.clean.3.5.3.tok.tc.sp.170
path_tgt: ptes/es.dtk.clean.3.5.3.tok.tc.sp.170
valid:
path_src: ptes/pt.dtk.clean.3.5.1.tok.tc.sp.170
path_tgt: ptes/es.dtk.clean.3.5.1.tok.tc.sp.170
# Vocabulary files that were just created
src_vocab: ptes/run/ptes_bl.vocab.src
tgt_vocab: ptes/run/ptes_bl.vocab.tgt
# Where to save the checkpoints
save_model: ptes/run/model
save_checkpoint_steps: 5000
train_steps: 100000
valid_steps: 10000
# Batching
queue_size: 10000
bucket_size: 32768
world_size: 2
gpu_ranks: [0,1]
batch_type: "tokens"
#batch_size: 4096
batch_size: 4096
valid_batch_size: 8
max_generator_batches: 2
accum_count: [4]
accum_steps: [0]
# Optimization
model_dtype: "fp32"
optim: "adam"
learning_rate: 2
warmup_steps: 8000
decay_method: "noam"
adam_beta2: 0.998
max_grad_norm: 0
label_smoothing: 0.1
param_init: 0
param_init_glorot: true
normalization: "tokens"
# Model
encoder_type: transformer
decoder_type: transformer
position_encoding: true
enc_layers: 6
dec_layers: 6
heads: 8
rnn_size: 512
word_vec_size: 512
transformer_ff: 2048
dropout_steps: [0]
dropout: [0.1]
attention_dropout: [0.1]
We build and train
onmt_build_vocab -config pt_es.yaml -n_sample -1 onmt_train -config pt_es.yaml
We have run the files with the files with and without this "statistical" cleaning.
There are two main steps. First we will use the all the files for each language to create a dictionary that we will use later to remove sentences from the previously "physical" cleaned bicorpus. We will try to remove sentences with low translation probability based in simple frequency rules.
The aim of these steps is create a dictionary of each language. This dictionary will contain the words (in lowercase) and the number of instances of each source/target word and its relation with words in the target/source sentence.
Files are:
es\pt\europarl-v10.pt/es.tsv
es\pt\news-commentary-v16.pt/es
es\pt\news.20xx.pt/es.shuffled.deduped
We need to extract the text from the europarl-v10.pt/es.tsv using a script (a_europarl_extrae.py)
es\pt\europarl-v10.pt/es.tsv -> es\pt\europarl-v10.pt/es
We join all es and pt mono files and remove duplicates.
copy es/pt mono.es/pt /B
This will create:
mono.es/pt
We then remove duplicates lines (ae_removedup.py):
mono.es/pt.ddp
perl detokenize.perl -l es
< /home/laika/unetbios/u_Mlai32/21_T4T/02_py/00_mono/data4/tmp/mono.es.ddp
> /home/laika/unetbios/u_Mlai32/21_T4T/02_py/00_mono/data4/tmp/mono.es.ddp.dtk
perl detokenize.perl -l pt
< /home/laika/unetbios/u_Mlai32/21_T4T/02_py/00_mono/data4/tmp/mono.pt.ddp
> /home/laika/unetbios/u_Mlai32/21_T4T/02_py/00_mono/data4/tmp/mono.pt.ddp.dtk
We run a physical cleaning with as we have done for bitext files (in this case script is for mono file). Script python is ag_manualcleanmono.py.
mono.es/pt.ddp.dtk -> mono.es/pt.ddp.dtk.0
We will use the script ah_manualcleannltkmono.py
mono.es/pt.ddp.dtk.0 -> mono.es/pt.ddp.dtk.clean
copy mono.pt.ddp.dtk.clean+pt.dtk.clean mono2.pt /B copy mono.es.ddp.dtk.clean+es.dtk.clean mono2.es /B
Removing duplicates with ae_removedup.py
mono2.pt/es ->mono2.pt/es.ddp
We could join mono2.pt/es.ddp to create a token list symbols (bc_normalizer_V02)
With ee_normaliza.py to tokenize the files using tag casing.
mono2.pt/es.ddp -> mono2.pt/es.ddp.tok
The script ai_remove_non_essential_infomono.py will remove variables, symbols (. , ; ....) and tags in order to tag uppercasing.
mono2.pt/es.ddp.tok -> mono2.pt/es.ddp.tok.ess
We will create a SQLite DB to store statistical information from the monocorpus (will provide the freq of a word in the corpus).
The db is created with a python script (sqlite_01_createdb.py)
dic_pt/es.db
This database was designed with the idea to handle upper and lowercase instances, also syllabic information, but for our statistical cleaning all instances will be lowered case.
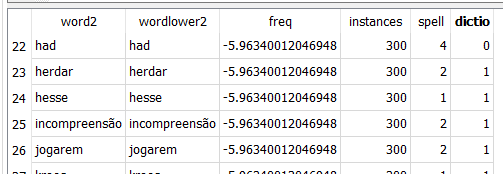
The program sqlite_02_anyadewords.py, creates 2 tables,
wordt (this table is not used, just as an internal first pass table) with the fields:
word -> word
wordlower -> lower(word)
instances -> number of instances
wordt2 (this table groups upper and lower instances of a wordlower from wordt, leaving word2 the word with more instances. Again, this feature is not used in this approach as all corpus is lower cased).
word2
wordlower2
freq -> frequency (log10(instances/Total number of words)
spell -> related
to spellcheck of this word:
spell=0 (failsspellcheck and has not enough frequency to be a valid word)
spell=1 (do not pass hunspell, nor upper word , but it has enough frequency to be included
as valid word in the dictonary.
spell=2 hunspell ok (all in dict)
spell= 3 probably a name (starts with upper and not spell=2). In dictionary if enough
frequency
spell= 4 not 2,3 and
passes english spellcheck test. All removed from dic
dic -> 0 this
word is not in the final dictionary, 1 file is in dictionary
instances -> number of instances
The final idea of these dictionaries is to find out if a word is in our corpus (dic=1). The words that can be in the dictionary are the ones that pass the spellcheck (spell=2), or have enough frequency (spell=1). (in this scenario there are no uppercase words (spell=3)
Here an example for portuguese.
Our starting point is the clean bilingual corpus we created:
es/pt.dtk.clean
What we will try to do is remove sentences from es/pt.clean with think they have low probability to be correct.
We will use the tokenized version:
es/pt.dtk.clean.tok.tc
es/pt.dtk.clean.tok.tc.var
We need the same format as we have used in the monocorpus, only sentences with lowercase words and no symbols, nor variables. We use the same program ai_remove_non_essential_infomono.py:
es/pt.dtk.clean.tok.tc -> es/pt.dtk.clean.tok.tc.plain
We have a python script that will read the previous file (all lowercase and without symbols or numbers), and will create python structures, with each word and its frequency
DOC1.pickle
DOC2.pickle
And another structure that will count instance relation with the words in each sentence. For example, if we have 2 sentences source (s) and target (t):
s1 s2 s3 s1
t1 t2
DICRel12.pickle
will hold:
s1, t1 -> 2
s1, t2 -> 2
s2, t1 -> 1
s2, t2 -> 1
s3, t1 -> 1
s3, t2 -> 1
This program is 01_corpuspre.py
This python script (10_sent_analyze.py), for each Si word in source sentence and Ti word in target sentence
... Si ...
.....Ti ...
We will try to find if P(Si|Ti) is significant versus the P(Si) (that is, in the population).
Other data we have is:
NSi -> Number of
instances of Si
NS -> Number of
source words
NTi -> Number of
instances of Ti
N(Si,Ti) -> Number of Si we find with Ti in the same sentence pair.
P(Si)=NSi/N is the probability in the bilingual corpus
We analyze the same probability in the sentences were Ti comes up:
P(Si|Ti) = N(Si,Ti)/NSi
If P(Si) is similar to P(Si|Ti) means that Ti does not "affect" the presence of Si, so is not its translation. On the other side if P(Si|Ti) means that Ti is probably the translation of Si.
In order to know if the difference is significant we establish a confidence margin for P(Si/Ti)
z=1.96 (95% confidence)
delta = z · sqrt( P(Si|Ti) * (1- P(Si|Ti)) /NSi).
If P(Si|Ti) is significant, we compare to P(Ti|Si) to assume the following should be close
P(Si|Ti) · P(T) similar to P(Ti|Si) · P(S) (the idea comes from bayes P(A|B)=P(B|A)*P(A)/P(B))
Based in this idea we are able to select the better P(Si|Ti) and score the sentence.
This part clearly can be improved/thinked as we have not have enough time review some of the hypothesis here. Because of this I will not enter in detail about the actual score. We used a:
pplex = Sum (log (P(Si|Ti) in the sentence)
but others are feasible.
The result of 10_sent_analyze.py is a working file:
es/pt.dtk.clean.tok.tc.plain -> es/pt.dtk.clean.tok.tc.plain.01
that will allow to select a line based in this score in the next program.
This cleaning is far from perfect. Some discarded sentences are probably more the result of the translator freedom to say something similar (some interpretation is always is present).
As an example, a sentence with a bad score (5.02):
NO 0.52705820382177 5.027419583493967 12 coeficiente de resistência específico
ao rolamento de todos os pneus do eixo
This matches to the actual pair:
CRR específico de todos los neumáticos en el eje 4
Coeficiente de resistência específico
ao rolamento de todos os pneus do eixo 4
So is a "bad" translation the acronym is used in ES (CRR) but is developed in PT (Coeficiente de resistência específico)
Another example with score 6.04:
NO 0.49301074293038244 6.048845822562368 6 ligas de alumínio em formas brutas
This matches to the actual pair:
Ligas de alumínio em formas brutas Aleaciones de aluminio en bruto
Correct translation in ES should be "en formas brutas" (similar to PT)
And finally another example with score 5.06
NO 0.5074609142266031 5.062647663811176 7 correspondência com acompanhamento
e localização de kg
This matches to the actual pair:
Correspondência com acompanhamento
e localização de 2 kg ;
carta con servicio de seguimiento y localización de 2 kg;
Probably there is a much better closer translation ("Correspondencia" is a very unusual way to say "carta con servicio").
A program (10_sent_analyze.py) will simply select the sentences with score better that the one specified (we used 3.5). The result is:
es.dtk.clean.3.5
pt.dtk.clean.3.5
(that is exactly the same as the original pt/es.dtk.clean but with the removed lines).
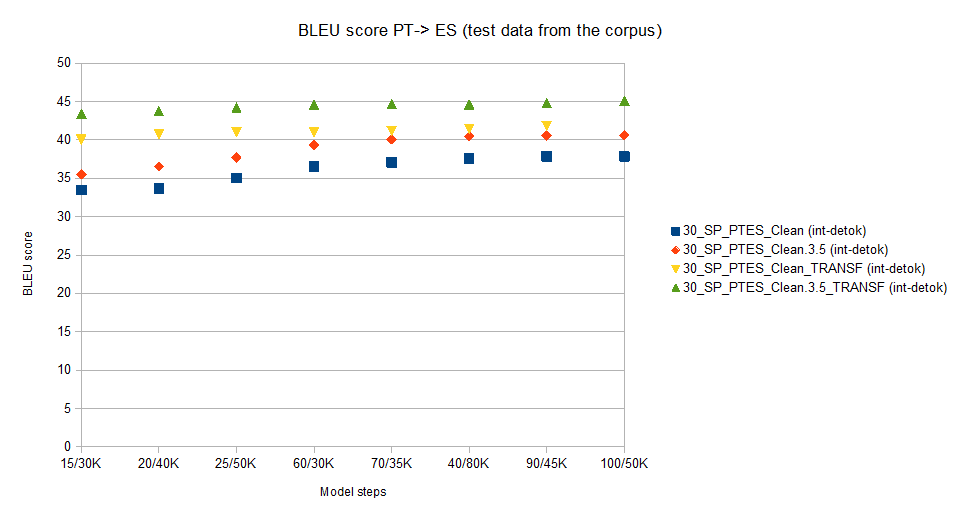
We will use the OpenNMT model to translate the file set (pt/es.dtk.clean.2) we set apart from the corpus to test its performance.
As the test data is from the corpus that has been used to create the model, its BLEU score will be much higher than the one we will obtain from test data unknown to the corpus.
For reference we will show values for a RNN model (notice how Transformer increases values aprox 10%)
Notice that using corpus statistically cleaned, BLEU score increases aprox 7,5%.
30_SP_PTES_Clean (int-detok) -> RNN model no "statistical" cleaning (Best value 37.87)
30_SP_PTES_Clean.3.5 (int-detok) -> RNN model with " statistical cleaning" (Best value 40.63)
30_SP_PTES_Clean_TRANSF (int-detok) -> Transformer model no "statistical" cleaning (Best value 41.85)
30_SP_PTES_Clean.3.5_TRANSF (int-detok) -> Transformer model with "statistical" cleaning" (Best value 45.11)
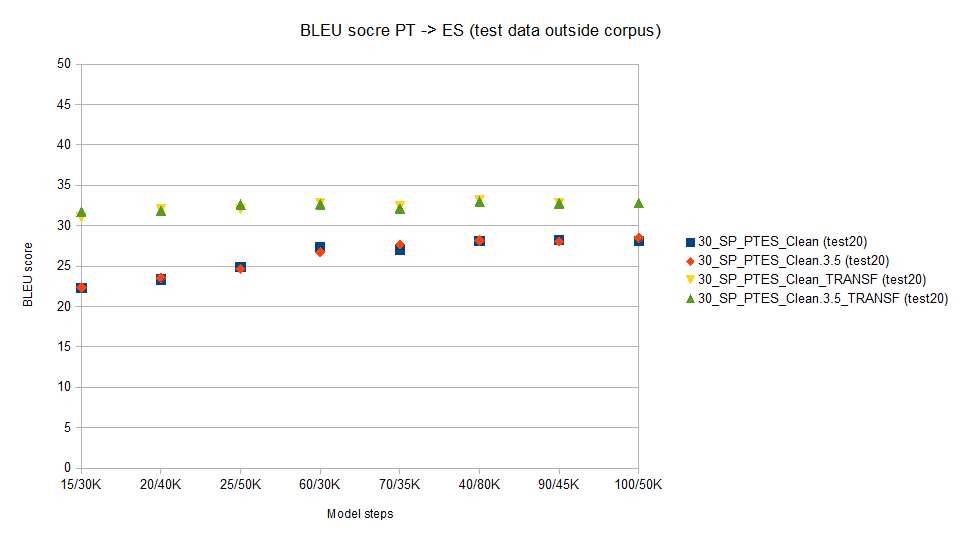
We will use the OpenNMT model to translate the file set (test20) previously unknown to the model. This test data is from last year.
As expected BLEU scores are much lower as the test data is seen by the model for the first time.
For reference we wil show values for a RNN model (notice how Transformer increases values aprox 15%)
Notice that using corpus statistically cleaned, BLEU score does not improve for data outside the corpus (a quite intersting finding)
30_SP_PTES_Clean
(test20) -> RNN model no "statistical" cleaning (Best
value 28.24)
30_SP_PTES_Clean.3.5
(test20) -> RNN model with " statistical cleaning" (Best
value 28.49)
30_SP_PTES_Clean_TRANSF
(test20) -> Transformer model no "statistical" cleaning
(Best value 32.77)
30_SP_PTES_Clean.3.5_TRANSF
(test20) -> Transformer model with "statistical"
cleaning" (Best value 32.99)
We would use the same files, now in an inverted way, but nothing new.
Even CA<>ES and PT<>ES are very similar languages, results in CA<>ES will be much better, highly probably because the corpus has better quality.
The only difference from the PT-ES flow is related to the catalan apostrophe, that in the past has been almost always the straight apostrophe ' (U+00027). This was used last year.
But more often we are finding the curly apostrophe ’ (U+02019), used now in most of the corpus.
So we had to create a program to handle this situation, converting all straight apostrophes in curly apostrophe.
Source data was provided by the organization in https://wmt21similar.cs.upc.edu/ . If anyone is interested I can share this data.
| DOGC v2 | DOGC.ca-es.es/ca |
| ParaCrawl | ParaCrawl_es-ca.txt |
| Wiki Titles v3 | wikititles-v3.ca-es.tsv |
Notice how we need to split the tsv in es/pt files (tsv are tab files). We used a script to split the tab value file (ad_SplitsTab.py) to create the parallel files
DOGC.ca-es.ca
DOGC.ca-es.es
ParaCrawl.ca
ParaCrawl.es
copy *.ca ca /B copy *.es es /B
or
cat .es es /B cat .ca ca /B
Unfortunately the corpus has many strings that look are tokenized, so we need to detokenize the files. The ways to detokenize the file is using the Moses detokenizer. This script will change some punctuation chars, so is a side effect that be take in account as not desirable.
Detokenize:
perl /home/laika/OpenNMT-py/tools/detokenize.perl -l es
< /home/laika/unetbios/u_Mlai32/21_T4T/02_py/02_bitext/data5/31_CAES/es
> /home/laika/unetbios/u_Mlai32/21_T4T/02_py/02_bitext/data5/31_CAES/es.dtk
perl /home/laika/OpenNMT-py/tools/detokenize.perl -l es
< /home/laika/unetbios/u_Mlai32/21_T4T/02_py/02_bitext/data5/31_CAES/ca
> /home/laika/unetbios/u_Mlai32/21_T4T/02_py/02_bitext/data5/31_CAES/ca.dtk
(CATALAN only, even after detokenization, still some issues with catalan apostrophe need to be fixed (on detokenized moses files) with file af_fix_catalan_moses.py )
ca.dtk -> ca.dtk.fixm
For sake of coherence we remove the .fixm
Remove duplicates (we use a script gg_RemoveDup.py)
ca.dtk-> ca.dtk
es.dtk-> es.dtk
Shffule the lines (we use a script hm_shuffle_bitex.py)
ca.dtk.ddup -> ca.dtk.ddup.shf
es.dtk.ddup -> es.dtk.ddup.shf
The corpus has 10.7 M lines
Beside the corpus, organization provides dev data that we have decided to use to train the model. This file is really small, so idea has been to add this dev data at the beginning of the corpus (our actual dev data will be sourced from the first lines of the corpus).
We detokenize the file as precaution.
perl /home/laika/OpenNMT-py/tools/detokenize.perl -l es
< /home/laika/unetbios/u_Mlai32/21_T4T/02_py/02_bitext/data5/31_CAES/dev.ca
> /home/laika/unetbios/u_Mlai32/21_T4T/02_py/02_bitext/data5/31_CAES/dev.ca.dtk
perl /home/laika/OpenNMT-py/tools/detokenize.perl -l es
< /home/laika/unetbios/u_Mlai32/21_T4T/02_py/02_bitext/data5/31_CAES/dev.es
> /home/laika/unetbios/u_Mlai32/21_T4T/02_py/02_bitext/data5/31_CAES/dev.es.dtk
Looks like file do not need to fix any apostrophe. We deduplicate the file as precaution (we use a script gg_RemoveDup.py)
dev.ca.dtk -> dev.ca.dtk.ddup
dev.es.dtk -> dev.es.dtk.ddup
We shuffle (we use a script hm_shuffle_bitex.py)
dev.ca.dtk.ddup - >
dev.ca.dtk.ddup.shf
dev.es.dtk.ddup - >
dev.ca.dtk.ddup.shf
Finally we join dev data with corpus
cat dev.ca.dtk.ddup.shf ca.dtk.ddup.shf > ca.dtk cat dev.es.dtk.ddup.shf es.dtk.ddup.shf > es.dtk
Our starting point is es.dtk and ca.dtk
We will perform a physical cleanning. These are ad-hoc tasks based on a manual inspection of the corpus:
- Sentences must to start with a char. (strings removed untill
char)
- Remove some (BAR) in bitext
- Sentece has to
have a hunspell valid word en each line.
- Remove starting
strings from sentences 123 .
- Remove starting strings from
sentences starting xxx)
- Remove any instances of (text
text.... )
- Remove any blank string
- Remove
duplicates
The result is:
es.dtk ->
es.dtk.0
ca.dtk ->
ca.dtk.0
We verify in es.dtk.0 and ca.dtk.0 all sentences in order to be splitted as sentences with nltk. If we do so, we ignore these sentences (probably 2 sentences or a translation as 2 sentences).
es.dtk.0 ->
es.dtk.clean
ca.dtk.0 ->
ca.dtk.clean
We will use a special tokenizer, that will tokenize all special chars from a token list file we will create first.
We create a working temporary file with the corpus (es.dtk.clean and ca.dtk.clean). The program we use is bc_normalizer_V02.py. The tokenizer uses an optional first phase in order to find the tokens it can use (with the special option "CREATELIST") that will generate a list of the split tokens (file *.tkl and *.tkl.error). As an example, this are the result of the first lines of *.tkl.freq for the full corpus (the token and the frequency)
list.tkl
The clean.tok.err
, 7243770 . 4484344 / 484058 ; 313478 - 300624 : 297728 " 238922 % 114370 ? 103638 ¿ 102222 [ 96742 ] 96470 ) 82760 » 81770
The result file just with the tags we will use for the our tokenizer will be clean.tkl
, . / ; - : " % ? ¿ [ ] ) . . .
Files ca/es.dtk.clean are ready for split in order to run OpenNMT.
But also, there is an optional "statistical" cleaning that will intended to use word probabilities in order to discard sentences with low probabilities. This is covered in 7 Statistical cleaning for CA<>ES
We use a script (hm_nlin_splitter.py) that will create 3 x 2 files:
ca/es.dtk.clean.1
(2000 lines, training data)
ca/es.dtk.clean.2
(2000 lines, test data)
ca/es.dtk.clean.3
(2761K lines, corpus)
Note: the start of the corpus contains the dev data for the organization.
We have created a special tokenizer that extracts numbers and assigns variables (ee_normaliza.py using function f_main_tokeniza). This tokenizer extracts numbers and handles correct spacing between special chars.
ca/es.dtk.clean.X
(X=1,2,3) ->
ca/es.dtk.clean.X.tok.tc
( tokenizer and casing)
ca/es.dtk.clean.X.tok.tc.var
(numerical values)
For example,
I Pilar va començar a reunir-se amb alguns familiars i amics per a practicar,
cantar i perfeccionar la composició, fins que el 29 de juny de 2015, en la
clausura del curs de la Universitat Sènior de la ciutat de Xàtiva,
es va estrenar l’himne de la Universitat de l’Experiència.
Mentre no es produeixi la creació de l’òrgan de gestió a què fa
referència l’article 5.2 d’aquests Estatuts, la gestió dels serveis
i activitats que exerceix la Mancomunitat de Municipis de l’Àrea Metropolitana
de Barcelona es durà a terme mitjançant els ens instrumentals de gestió
directa de la pròpia Mancomunitat que aquesta determini.
Will be converted in
⦅up⦆ i ⦅up⦆ pilar va començar a reunir @@-@@ se amb alguns familiars i amics per a practicar @@,
cantar i perfeccionar la composició @@, fins que el ⦅n0⦆ de juny de ⦅n1⦆ @@, en la
clausura del curs de la ⦅up⦆ universitat ⦅up⦆ sènior de la ciutat de ⦅up⦆ xàtiva @@,
es va estrenar l @@’@@ himne de la ⦅up⦆ universitat de l @@’@@ ⦅up⦆ experiència @@.
⦅up⦆ mentre no es produeixi la creació de l @@’@@ òrgan de gestió a què fa
referència l @@’@@ article ⦅n0⦆ @@.@@ ⦅n1⦆ d @@’@@ aquests ⦅up⦆ estatuts @@, la gestió dels serveis
i activitats que exerceix la ⦅up⦆ mancomunitat de ⦅up⦆ municipis de l @@’@@ ⦅up⦆ àrea ⦅up⦆ metropolitana
de ⦅up⦆ barcelona es durà a terme mitjançant els ens instrumentals de gestió
directa de la pròpia ⦅up⦆ mancomunitat que aquesta determini @@.
In order to feed OpenNMT we need to BPE the files.
Train and encoding (we use es+ca to create our vocabulary)
spm_train
--input=ca.dtk.clean.1.tok.tc,es.dtk.clean.1.tok.tc,ca.dtk.clean.3.tok.tc,es.dtk.clean.3.tok.tc
--model_prefix=bpe --vocab_size=16000 --character_coverage=1 --model_type=bpe
-user_defined_symbols=⦅up⦆,⦅aup⦆,⦅n0⦆,⦅n1⦆,⦅n2⦆,⦅n3⦆,⦅n4⦆,⦅n5⦆,⦅n6⦆,⦅n7⦆,⦅n8⦆,⦅n9⦆
spm_encode --model=bpe.model --output_format=piece --extra_options=bos:eos
< ca.dtk.clean.1.tok.tc > ca.dtk.clean.1.tok.tc.sp
spm_encode --model=bpe.model --output_format=piece --extra_options=bos:eos
< es.dtk.clean.1.tok.tc > es.dtk.clean.1.tok.tc.sp
spm_encode --model=bpe.model --output_format=piece --extra_options=bos:eos
< ca.dtk.clean.2.tok.tc > ca.dtk.clean.2.tok.tc.sp
spm_encode --model=bpe.model --output_format=piece --extra_options=bos:eos
< es.dtk.clean.2.tok.tc > es.dtk.clean.2.tok.tc.sp
spm_encode --model=bpe.model --output_format=piece --extra_options=bos:eos
< ca.dtk.clean.3.tok.tc > ca.dtk.clean.3.tok.tc.sp
spm_encode --model=bpe.model --output_format=piece --extra_options=bos:eos
< es.dtk.clean.3.tok.tc > es.dtk.clean.3.tok.tc.sp
As long length for strings is an issue for the neuronal network. We will use another script (hn_maxlinlincropy.py) to delete lines with length greater than 170 tokens (notice lines are tokenized + BPE). This will mean removing less than 5% of the vocabulary but greatly reduces memory consumption on the GPUs.
Final result files are:
ca.dtk.clean.1.tok.tc.sp.170
(training)
es.dtk.clean.1.tok.tc.sp.170
(training)
es.dtk.clean.3.tok.tc.sp.170
(corpus)
ca.dtk.clean.3.tok.tc.sp.170
(corpus)
docker run --rm -it \
--mount type=bind,source="$HOME"/u,target=/u \
--mount type=bind,source="$HOME"/unvme,target=/unmve \
--mount type=bind,source="$HOME"/unetbios/u_Mlai32,target=/u_Mlai32 \
--gpus '"device=0"' \
laika/openmnt:T4T
This is the yaml file for the CA->ES and the Transformer model
data:
corpus_1:
path_src: caes/ca.dtk.clean.3.5.3.tok.tc.sp.170
path_tgt: caes/es.dtk.clean.3.5.3.tok.tc.sp.170
valid:
path_src: caes/ca.dtk.clean.3.5.1.tok.tc.sp.170
path_tgt: caes/es.dtk.clean.3.5.1.tok.tc.sp.170
# Vocabulary files that were just created
src_vocab: caes/run/caes_bl.vocab.src
tgt_vocab: caes/run/caes_bl.vocab.tgt
# Where to save the checkpoints
save_model: caes/run/model
save_checkpoint_steps: 5000
train_steps: 100000
valid_steps: 10000
# Batching
queue_size: 10000
bucket_size: 32768
world_size: 2
gpu_ranks: [0,1]
batch_type: "tokens"
#batch_size: 4096
batch_size: 4096
valid_batch_size: 8
max_generator_batches: 2
accum_count: [4]
accum_steps: [0]
# Optimization
model_dtype: "fp32"
optim: "adam"
learning_rate: 2
warmup_steps: 8000
decay_method: "noam"
adam_beta2: 0.998
max_grad_norm: 0
label_smoothing: 0.1
param_init: 0
param_init_glorot: true
normalization: "tokens"
# Model
encoder_type: transformer
decoder_type: transformer
position_encoding: true
enc_layers: 6
dec_layers: 6
heads: 8
rnn_size: 512
word_vec_size: 512
transformer_ff: 2048
dropout_steps: [0]
dropout: [0.1]
attention_dropout: [0.1]
We buid and train
onmt_build_vocab -config ca_es.yaml -n_sample -1 onmt_train -config ca_es.yaml
We have run the files with the files with and without this "statistical" cleaning.
There are two main steps. First we will use the all the files for each language to create a dictionary that we will use later to remove sentences from the previously "physical" cleaned bicorpus. We will try to remove sentences with low translation probability based in simple frequency rules.
The aim of these steps is create a dictionary of each language. This dictionary will contain the words (in lowercase) and the number of instances of each source/target word and its relation with words in the target/source sentence.
For es will use the mono.es created for ES-CA
For catalan, only one file: cawac.uniq.sortr. We need to detokenize:
perl detokenize.perl -l es
< /home/laika/unetbios/u_Mlai32/21_T4T/02_py/00_mono/data5/cawac.uniq.sortr
> /home/laika/unetbios/u_Mlai32/21_T4T/02_py/00_mono/data5/cawac.uniq.sortr.dktThen apply the fix for the catalan apostrophe. af_fix_catalan_moses.py.
Last step is add all bilingual catalan files (ca.dtk.clean and es.dtk.clean) to mono.es and cawac.uniq.sortr.dkt
copy es.dtk.clean + mono.es tmp.es /B copy ca.dtk.clean + cawac.uniq.sortr.dkt.fixm tmp.ca /B
We remove duplicates with ae_removedup.py
tmp.es ->
mono.es.dpp
tmp.ca ->
mono.ca.ddp
Note: The name is misleading because it says "mono", but already we have added the "bicorpus".
perl detokenize.perl -l es
< /home/laika/unetbios/u_Mlai32/21_T4T/02_py/00_mono/data4/mono.es.ddp
> /home/laika/unetbios/u_Mlai32/21_T4T/02_py/00_mono/data4/mono.es.ddp.dtk
perl detokenize.perl -l es
< /home/laika/unetbios/u_Mlai32/21_T4T/02_py/00_mono/data4/mono.ca.ddp
> /home/laika/unetbios/u_Mlai32/21_T4T/02_py/00_mono/data4/mono.ca.ddp.dtk
We run a physical cleaning with as we have done for bitext files (in this case script is for mono file). Script python is ag_manualcleanmono.py.
Result: mono.es/ca.ddp.dtk.0
We will use the script ah_manualcleannltkmono.py
ah_manualcleannltkmono.py -> mono.es/ca.dtk.ddp.clean
With ee_normaliza.py to tokenize the files using tag casing.
mono.ca.ddp.clean ->
mono.ca.ddp.clean.tok.tc
mono.es.ddp.clean ->
mono.es.ddp.clean.tok.tc
The script ai_remove_non_essential_infomono.py will remove variables, symbols (. , ; ....) and tags in order to tag uppercasing.
mono.ca.ddp.clean.tok.tc
-> mono.ca.ddp.clean.tok.tc.ess
mono.es.ddp.clean.tok.tc
-> mono.es.ddp.clean.tok.tc.ess
We will create a SQLite DB to store statistical information from the monocorpus (will provide the freq of a word in the corpus).
The db is created with a python script (sqlite_01_createdb.py)
dic_ca/es.db
Same as in pt<>es (3.1.11 Addition of monocorpus data to sqlite db)
Our starting point is the clean bilingual corpus we created:
es/ca.dtk.clean
We will repeat the same steps as we did for ES<>CA.
As the ES<>CA corpus was quite bigger we need to split the original es/ca.dtk.clean en 3 files, and the results were joined as:
es/ca.dtk.clean.3.5
What we will try to do is remove sentences from es/pt.clean with think they have low probability to be correct.
We will use the tokenized version:
es/ca.dtk.clean.tok.tc es/ca.dtk.clean.tok.tc.var
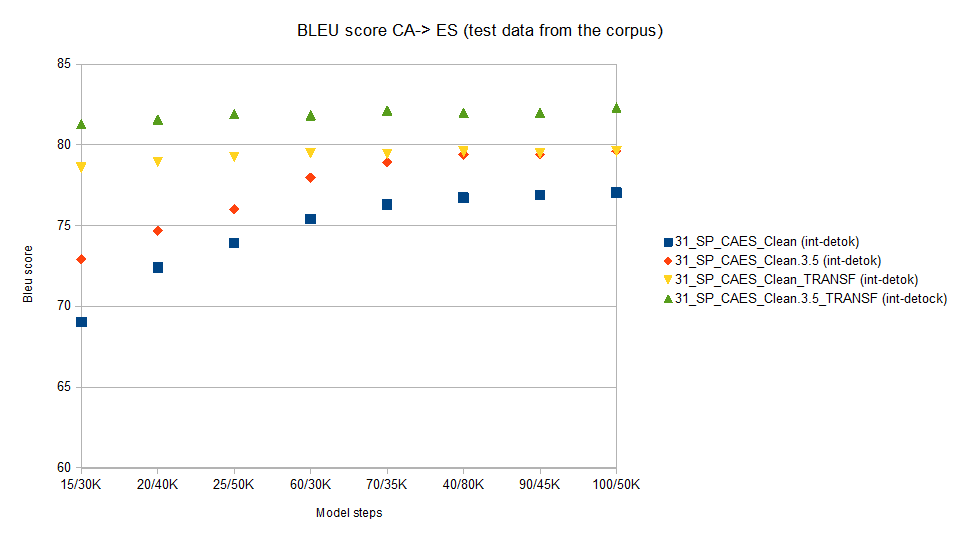
We will use the OpenNMT model to translate the file set (ca/es.dtk.clean.2) we set apart from the corpus to test its performance.
As the test data is from the corpus that has been used to create the model, its BLEU score will be much higher than the one we will obtain from test data unknown to the corpus.
For reference we wil show values for a RNN model (notice how Transformer increases values aprox 3.3%)
Notice that using corpus statistically cleaned, BLEU score increases aprox 3.4%.
31_SP_CAES_Clean
(int-detok) -> RNN model no "statistical" cleaning
(Best value 77.04)
31_SP_CAES_Clean.3.5
(int-detok) -> RNN model with " statistical cleaning"
(Best value 79.61)
31_SP_CAES_Clean_TRANSF
(int-detok) -> Transformer model no "statistical"
cleaning (Best value 79.6)
31_SP_CAES_Clean.3.5_TRANSF
(int-detock) -> Transformer model with "statistical"
cleaning" (Best value 82.32)
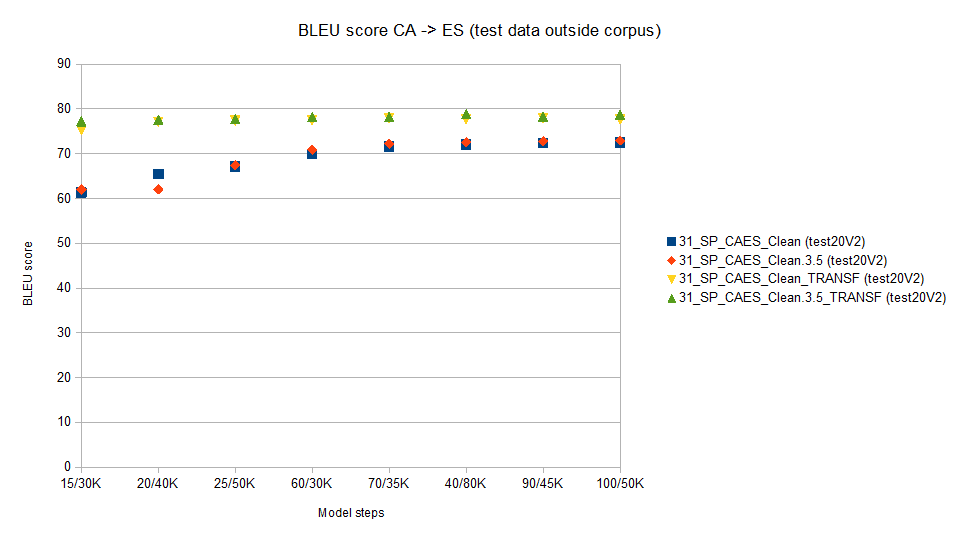
We will use the OpenNMT model to translate the file set (test20) previously unknown to the model. This test data is from last year.
As expected BLEU scores are much lower as the test data is seen by the model for the first time.
For reference we wil show values for a RNN model (notice how Transformer increases values aprox 7,5%)
Notice that using corpus statistically cleaned, BLEU score does not improve (a quite intersting finding)
31_SP_CAES_Clean
(test20V2) -> RNN model no "statistical" cleaning (Best
value 72.47)
31_SP_CAES_Clean.3.5
(test20V2) -> RNN model with "stistical cleaning" (Best
value 72.91)
31_SP_CAES_Clean_TRANSF
(test20V2)-> Transformer model no "statistical" cleaning
(Best value 77.61)
31_SP_CAES_Clean.3.5_TRANSF
(test20V2) -> Transformer model with "statiscial"
cleaning" (Best value 78.71)
OpenNMT has been run in a docker environment, based in:
FROM pytorch/pytorch:1.9.0-cuda10.2-cudnn7-runtime
#
# Update the image to the latest packages
RUN apt-get update && apt-get upgrade -y
#
RUN apt install git -y
RUN apt install nano
# Locale UTF8 https://stackoverflow.com/questions/27931668/encoding-problems-when-running-an-app-in-docker-python-java-ruby-with-u
RUN apt-get update && apt-get install -y locales && locale-gen en_US.UTF-8
RUN locale-gen en_US.UTF-8
ENV LANG en_US.UTF-8
ENV LANGUAGE en_US:en
ENV LC_ALL en_US.UTF-8
# sentence piece
# from https://github.com/google/sentencepiece
RUN apt-get install cmake build-essential pkg-config libgoogle-perftools-dev -y
RUN git clone https://github.com/google/sentencepiece.git && \
cd sentencepiece && \
mkdir build && \
cd build && \
cmake .. && \
make -j $(nproc) && \
make install && \
ldconfig -v
RUN cd ../..
RUN git clone https://github.com/OpenNMT/OpenNMT-py.git && \
cd OpenNMT-py && \
pip install -e .
Typical run docker run (2 GPU binding to couple of directories. Docker image name "laika/opennmet:T4T")
docker run --rm -it \
--mount type=bind,source="$HOME"/u,target=/u \
--mount type=bind,source="$HOME"/unvme,target=/unmve \
--mount type=bind,source="$HOME"/unetbios/u_Mlai32,target=/u_Mlai32 \
--gpus '"device=0,1"' \
laika/openmnt:T4T